På alla hjärtans dag 2025 släppte KB-labb vid Kungliga biblioteket sin egen finjusterade version av OpenAI:s Whisper-modeller. De tränade om modellerna med tusentals timmar av ljud från både SVT och riksdagsdebatter. Tyvärr, för att undvika juridiska problem och för att hålla fokus på sitt uppdrag, tillhandahåller labbet endast modellernas öppna vikter.
Så jag ägnade några timmar åt att bygga ett webbgränssnitt för att använda modellerna så enkelt som möjligt. Jag kallade det Whisper-Web.
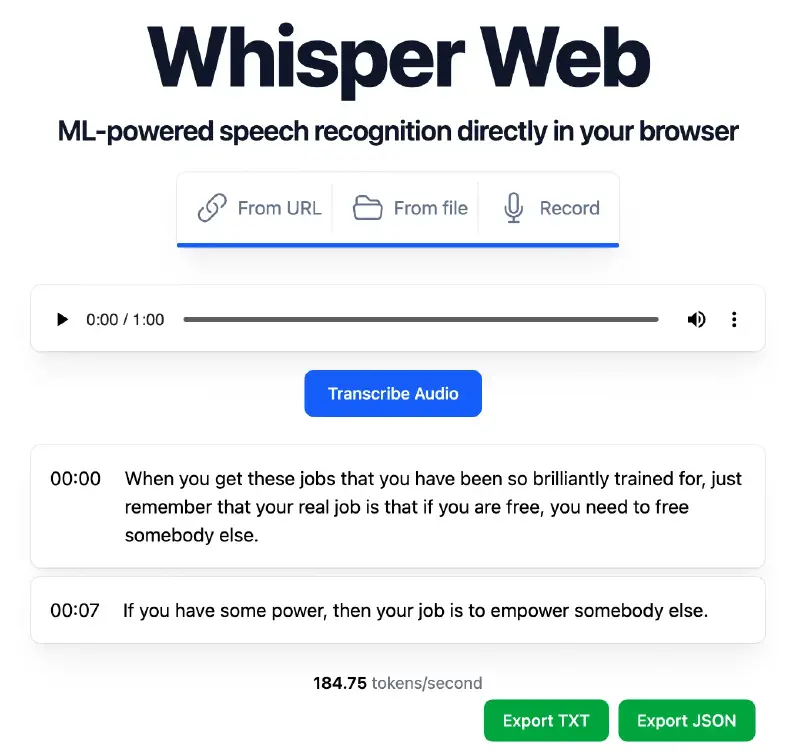
Första gången du laddar upp en fil kommer den att ladda ner en AI-modell och utföra transkriberingen lokalt i din webbläsare. Detta innebär att din ljudfil aldrig lämnar din enhet. Det betyder också att transkriberingen blir långsam eller misslyckas om din dator eller smartphone inte är tillräckligt kraftfull för att utföra den.
I inställningarna kan du välja mellan olika modeller och olika kvantiseringsnivåer. En mindre modell med lägre kvantisering går snabbare men gör fler misstag. Som standard använder Whisper-web små modeller, men du kan prova en större och se om den fungerar på din enhet.
I appen kan användaren välja mellan de svenska modellerna, norska modeller (från det norska nationalbiblioteket) och OpenAI:s modeller som är bäst på alla andra språk.
Detta projekts kod är faktiskt en fork av en demo skapad av Xenova som jag har uppdaterat och förbättrat. Båda är tillgängliga på Github. Använd gärna koden eller bidra till projektet.
